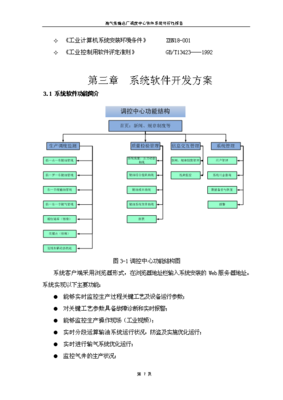
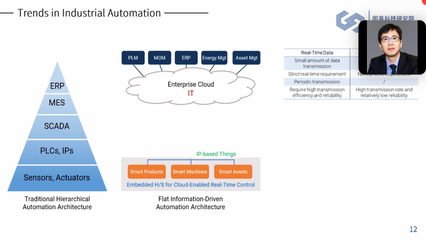
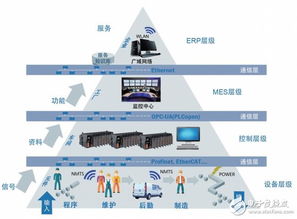
在智能制造與工業4.0的浪潮下,工業產品UI設計正從輔助性環節演變為驅動工業軟件變革的核心力量。其未來發展前景,將不再局限于界面的美化,而是深度融合用戶體驗、數據智能與工業場景,重塑人機交互范式,引領工業軟件開發進入一個更高效、更人性化、更智能的新紀元。
1. 從“可用”到“善用”:用戶體驗的深度賦能
傳統的工業軟件UI往往以功能實現為第一要務,界面復雜,學習成本高。未來的發展趨勢將徹底轉向以“人”為中心。設計將深入理解工程師、操作員、維護人員等不同角色的工作流程、認知習慣與情感需求。通過任務分析、情境化設計,UI將提供高度個性化、引導式的工作界面,降低認知負荷,將復雜的工業邏輯轉化為直觀的操作。例如,針對故障診斷場景,UI可能通過增強現實(AR)疊加、三維可視化與步驟引導,讓維護人員能快速定位問題,實現從“知道如何操作”到“順暢高效完成”的跨越。
2. 數據可視化與智能決策支持
工業環境正產生海量數據。未來的工業UI設計核心挑戰與機遇在于,如何將這些數據轉化為可操作的洞察。UI將成為數據的“翻譯官”與“導航儀”。動態數據儀表盤、實時三維模擬、預測性維護的可視化預警、基于AI的異常模式高亮顯示等將成為標配。設計不再僅僅呈現數據,而是通過視覺敘事,揭示數據背后的關聯、趨勢與風險,輔助用戶進行快速、精準的決策。例如,在能源管理系統中,UI可能通過熱力圖、流向圖直觀展示能耗峰值與異常,并智能推薦優化策略。
3. 多模態交互與沉浸式體驗
隨著XR(擴展現實)、語音識別、手勢控制等技術的成熟,工業軟件的人機交互方式將極大豐富。UI設計將突破二維屏幕的限制,走向三維空間與多感官通道。在工廠規劃、設備維修、遠程協作等場景中,AR/VR界面將允許工程師在虛擬環境中“觸摸”和操作設備原型。語音指令可用于在雙手被占用時控制軟件。多模態交互的融合設計,將創造更自然、沉浸、高效的作業環境,尤其適用于復雜或高危的工業現場。
4. 平臺化、模塊化與設計系統
工業軟件生態日趨復雜,涵蓋設計、仿真、生產、運維等多個環節。未來的UI設計將更加強調一致性與可擴展性。通過建立統一的設計語言系統,確保不同模塊、不同終端(桌面、移動端、可穿戴設備)間的體驗連貫性。模塊化組件庫允許快速搭建和迭代針對特定行業或工作流的界面,加速軟件開發。平臺化思維也使UI能夠更好地集成第三方工具和數據源,形成協同工作的統一門戶。
5. 智能化與自適應界面
AI將深度融入UI的生成與演化過程。界面將具備“感知-響應”能力,能夠根據用戶角色、當前任務、技能水平、操作歷史甚至實時生理狀態(在安全合規前提下)動態調整布局、信息密度和交互復雜度。新手可能看到更多引導和解釋,而專家則獲得最簡潔高效的專業工具鏈。AI輔助設計工具也將幫助設計師自動生成布局、檢查可用性、進行A/B測試,極大提升設計效率與科學性。
6. 安全與可靠性的前置設計考量
工業環境對安全、可靠、容錯的要求極高。UI設計必須將安全性作為底層原則。這包括清晰的權限與狀態指示、防誤操作設計(如關鍵操作的多重確認)、異常情況的明確告警與恢復指引、以及符合行業安全規范的視覺編碼(如顏色、圖標在特定場景下的標準化使用)。未來的設計將更注重在提升效率的構建堅固的“防錯”與“容錯”用戶體驗防線。
對工業軟件開發的影響
上述趨勢將深刻改變工業軟件開發的模式:
- 開發流程變革:UI/UX設計將更早、更深入地介入產品定義與架構階段,與領域專家、開發工程師形成緊密協作的“鐵三角”。
- 技術棧融合:前端技術需要與數據可視化庫(如Three.js, D3.js)、游戲引擎(用于高保真仿真)、AR/VR SDK以及后端AI服務深度集成。
- 人才需求復合化:亟需既懂工業知識、人機交互,又具備數據思維和一定技術理解力的復合型設計師。
###
工業產品UI設計的是向著更智能、更沉浸、更人性化、更安全的方向演進。它將從軟件的“皮膚”進化為工業智能系統的“神經中樞”與“交互界面”,其價值將從提升美觀度升維至提升生產力、決策質量與工作安全。對于工業軟件開發而言,擁抱以體驗驅動、數據智能、多模態融合為特征的新一代UI設計,不僅是提升產品競爭力的關鍵,更是賦能工業數字化轉型、釋放人才創造力的必經之路。